논문명: Deep Learning for Image Super-resolution: A Survey
저자: Zhihao Wang, Jian Chen, Steven C.H. Hoi
게재연도: 2020년.
Introduction
이 논문은 Deep Learning 기반의 SR 기술에 대해 소개한다. 다른 survey 논문들과는 다르게 이 논문에서는 딥러닝 기반의 SR 기술에 대해서만 집중적으로 다룬다.
이 논문에서는 아래의 정보를 제공한다.
(1) Deep learning 기반 image super-resolution techniques
(2) Problem settings
(3) Benchmark datasets
(4) Performance metrics
(5) A family of SR methods with deep learning
(6) Domain-specific SR applications.
Problem Setting and Terminology

Image super-resolution은 low-resolution(LR)이미지를 high-resolution(HR)이미지로 복원하는 것을 의미한다. 일반적으로 LR 이미지 생성 모델은 수식 1의 결과로 나타낸다. D는 해상도 저하 함수이고, $I_y$는 HR이미지를 의미하고, $\delta$는 해상도 저하 품질의 파라미터를 의미한다.
일반적으로는 이미지 해상도 저하 과정은 알 수 없고, 오직 LR 이미지만 제공된다. 이런 경우를 blind SR 이라고 한다.

Blind SR의 경우 주어진 $I_x$를 ground truth HR 이미지인 $I_y$와 유사한 $\hat{I}_y$이미지로 복원해야 한다.
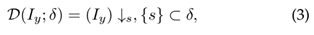
대다수에서는 LR 이미지를 만들 때, 수식 3과 같은 방법을 사용한다. $↓_s$는 downsampling(이미지 축소)을 의미하며 s는 scaling factor이다. 대다수의 SR datasets은 이 방법대로 down-sampling을 한 후에 bicubic(with anti aliasing)으로 해상도를 키우는 방법으로 생성되었다.

단순히 down-sampling이 아닌 blur kernel $\kappa$를 이미지와 컨볼루션한 후에 down-samping하고, 추가적으로 Gaussian noise를 첨가하는 방법(수식 4)도 있으며, 이 방법이 현실에서 나타나는 LR 이미지와 더 가까우며, SR알고리즘을 개발하는데 더 유리하다.

마지막으로 SR은 수식 5로 정의한다. $L(\hat{I}_y,I_y)$는 복원한 HR 이미지 $\hat{I} _y$와 ground truth $I_y$ 사이의 loss function 이며, $\Phi(\theta)$는 regularization term(일반화를 위한 term) 이다($\lambda$는 tradeoff 파라미터). 일반적으로 SR에서 많이 사용되는 loss function은 pixel 단위로 mean squared error(pixel loss)이지만, 좀 더 성능이 좋은 모델은 여러 loss를 함께 사용하는 경향이 있다.
Datasets for Super-resolution
Table1. List of public image datasets for super-resolution benchmarks.

Table 1은 SR연구에서 사용되는 datasets을 나타낸다. 대다수의 dataset이 HR-LR 쌍으로 제공하지만, HR만 제공하는 경우도 있다. HR만 제공하는 경우에는 LR을 직접 생성해서 사용한다(앞에서 설명한 down-sampling 등의 방법으로 생성).
Table1 의 datasets 뿐만 아니라, ImageNet, MS-COCO, VOC2012, CelebA 등 다른 vision 분야에 사용되는 dataset도 SR에 활용 가능하다.
Image Quality Assessment
객관적인 화질평가(the objective IQA(Image Quality Assessment))는 세가지 방법으로 나뉜다.
(1) Full-reference methods: 평가에 레퍼런스 이미지를 사용하는 방법
(2) Reduced-reference methods: 이미지에서 추출한 특징으로 비교하는 방법
(3) No-reference methods: 어떠한 레퍼런스도 사용하지 않는 방법
Peak Signal-to-Noise Ratio
Peak signal-to-noise ratio(PSNR)은 이미지 손실변환(압축 등) 등의 작업에서 복원하였을 때에 이미지 품질을 평가하는 대표적인 방법이다. 이미지 SR에서 PSNR은 pixel 최댓값($L$로 정의)과 mean squared error(MSE)를 이용하여 계산한다.

Ground truth 이미지 $I$가 주어졌을 때($N$은 pixel 개수), 복원된 이미지는 $\hat{I}$이고, PSNR은 수식 6으로 정의한다. 위 수식에서 $L$은 8bit 이미지의 경우 255를 의미한다.
PSNR방법은 오직 pixel로 계산한 MSE를 반영하므로, 시지각(visual perception)을 반영하지 못한다. 이로 인해, 이를 loss로 반영하면 사람의 인식이 중요한 분야의 real scence에서 복원품질의 저하로 나타난다. 하지만, 시지각을 완벽하게 반영할 방법이 없기에 PSNR은 SR모델에서 여전히 많이 사용되는 방법이다.
Structural Similarity
Structural Similarity Index Measure(SSIM)은 이미지 간의 구조의 유사성을 이용하여 평가하는 방법이며, 사람의 시각 시스템이 이미지에서 구조정보를 추출하는데 매우 적합하다는 점을 고려한 방법이다.
$N$ pixels의 이미지 $I$가 있으면, 밝기(luminance) ${\mu}_I$, 대비 $\sigma_I$를 평균과 표준편차로 각각 평가한다. 예를들어, $\mu_I = \frac{1}{N} \Sigma^N_{i=1}I(i)$ 이다.
각 이미지들의 밝기와 대비를 이용하여 아래 $C_l(I,\hat{I})$과 $C_c(I,\hat{I})$을 나타낸다.

$C_1 =(\kappa_1L)^2$ 와 $C_2=(\kappa_2L)^2$는 불안정성을 피하기 위한 상수이다. $\kappa_1$과 $\kappa_2$는 1보다 작은 수다.
계산이 유도하는 것은, 이미지의 구조를 정규화된 픽셀 값으로 나타내고($\frac{(I-\mu_I)}{\sigma_I}$), 이 픽셀 계산 값들은 구조적 유사성을 측정하는 것이며, 이는 두 이미지($I$,$\hat{I}$)의 상관계수와 동일하다는 것이다.
따라서 구조를 비교하는 함수 $C_s(I,\hat{I})$는 아래와 같이 정의한다.

위 식에서 $\sigma_{I,\hat{I}}$은 이미지 $I$와 $\hat{I}$ 사이의 공분산(covariance)이며, $C_3$는 안정화를 위한 상수이다. 결과적으로 SSIM은 아래와 같이 주어진다.

$\alpha, \beta, \gamma$는 상대적 중요도를 조정하기 위한 파라미터이다.
정리하면, SSIM은 인간의 시각시스템의 관점에서 이미지 복원 품질을 평가하는 방법이며, 시지각 평가 관점에서 더욱 알맞은 방법이며, 많이 사용되는 방법이다.
Mean Opinion Score
Mean opinion score(MOS) 방법은 주관적인 IQA 방법이며, 평가자에게 1(bad)부터 5(good)까지 평가를 요청하는 것이다. 최종적으로는 평균 점수를 반영한다.
MOS는 평가자의 편향이나 변덕 등 비선형적인 요소가 있다는 본질적인 문제가 있지만, 일반적인 IQA방법에 의해서는 성능이 떨어지지만 시지각 품질 면에서는 우수한 SR모델들이 있다. 이러한 모델을 평가할 때는 MOS 방법이 우수하다.
Learning-based Perceptual Quality
Large datasets을 학습하여 이미지의 품질을 평가하는 방법에 대해 소개한다.
Ma(Ma et al.[66]) NIMA(Talebi et al.[67]) 등의 방법이 ground-truth 이미지 없이 이미지의 품질을 평가하는 방법이고, DeepQA(Kim et al.[68])은 distorted image, objective error maps, and subjective scores으로 triplet loss를 계산하고 학습하여 시각 유사성(visual similarity)을 예측한다.
2.4 Operating Channels
Color space로는 공통적으로 RGB가 많이 사용되나, YCbCr color space도 많이 사용된다. YCbCr은 Y, Cb, Cr 채널로 구성되고, 각각 밝기(luminance), blue-색차, red-색차를 의미한다.
초기 SR연구에서는 YCbCr color space가 사용되었으나 요즘에는 RGB color space가 사용되는 경향이 있다.
2.5 Super-resolution Challenges
SR 분야에는 NTIRE와 PIRM challenge가 있다.
(1) NTIRE(New Trend in Image Restoration and Enhancement): CVPR에서 개최되는 challenge이며, SR을 비롯한 denoising, colorization 등을 다룬다. SR분야에서는 DIV2K 데이터셋을 사용하며, 이 데이터셋은 bicubic downscaling track과 blind track으로 구성되어 있다. Blind track은 실제 발생하는 것처럼 이미지 저하요소를 알 수 없는 것이다.
(2)PIRM(Perceptual Image Restoration and Manipulation): ECCV에서 개최되는 challenge이다. PIRM은 이미지의 생성 정확도(generation accuracy)와 인지 품질(perceptual quality) 사이에 발생하는 trade-off 관계를 다루며, 또 다른 sub-challenge는 스마트폰 환경에서의 SR을 다룬다.
3. SUPERVISED SUPER-RESOLUTION
근래 연구자들은 LR 이미지와 HR이미지를 모두 학습하는 딥러닝 기반의 SR 알고리즘들을 제안해왔다. 많은 연구들이 제안되었지만, 이 연구들은 model frameworks, upsampling methods, network design, and learning strategies 들을 적절히 조합한 것이 핵심이다.
3.1 Super-resolution Frameworks
Image super-resolution은 문제가 잘 정의되지 않으므로, 어떻게 upsampling을 수행할 것인지가 핵심이다. 다양한 모델들의 구조가 있지만, 사용된 upsampling 방법과 모델 내의 위치에 따라 4개의 model frameworks로 구분할 수 있다(Fig.2)
(1) Pre-upsampling Super-resolution

이 방법은 Dong et al.[22,23]의 연구에서 처음 제안된 방법으로 SRCNN에서 사용된 방법이다. Low-dimensional space에서 high-dimensional space로 바로 맵핑하여 학습하는 것이 어려운 관계로, 우선 upsampling 알고리즘을 사용하여 이미지를 원하는 크기의 고해상도로 1차적으로 변환하고(coarse HR images), 이 후에 딥러닝을 사용하여 이미지를 개선하는 방법이다.
장점: SR에서 가장 어려운 이미지 크기를 키우는 upsampling task를 완료하였기 때문에 딥러닝 모델은 조잡한 이미지를 개선하는데 학습을 집중할 수 있어서, 학습 난이도를 줄일 수 있다.
단점: predefined upsampling은 노이즈 증폭이나 blur와 같은 부작용이 있다(noise나 blur같은 것도 같이 upsampling하기 때문인 것 같음). 그리고 모든 딥러닝 연산을 high-dimensional space에서 하기 때문에 모델 학습 및 운용에 비용이 가장 많이 소요된다.
(2) Post-upsampling Super-resolution

이 방법은 computational cost를 효율적으로 하기 위해, 모든 딥러닝 연산을 low-dimensional space에서 진행하고, 모델의 끝에 학습이 가능한 upsampling layers를 배치하였다.
특징 추출과 같은 computational cost가 많이 소모되는 것들은 전부 low-dimensional space에서 이루어 지고, 마지막에 upsampling 을 하였기 때문에 효율이 좋다.
(3) Progressive Upsampling Super-resolution

Post-upsamping 방법은 우수한 방법이지만, low-dimensional space에서 high-dimensional space로 변화하는 과정이 단 한번의 step으로 이루어지기 때문에 학습난이도가 높다는 문제가 있다. 그리고 SR을 원하는 scale factor에 대해 모두 개별 학습해야한다는 단점이 있다.
이런 문제를 극복하기 위해서 progressive upsampling 방법이 제안되었다. Progressive upsampling 방법은 여러개의 CNN 모델 구조로 이루어져 있으며, 각 CNN 모델들은 이미지를 점진적으로 upsamping 해나간다. 이러한 방법은 기존에 학습하기 어려웠던 한번에 큰 이미지로 uupsampling하는 것을 여러 단계로 나누어 upsampling함으로써 학습 난이도를 낮추게 한다. 특히 multi-scale SR과정에서 낭비되는 리소스 없이 할 수 있다(Post-upsampling 방법은 각 scale마다 별도로 학습을 해야함).
이 모델의 단점으로는 여러 단계의 CNN 모델 구조의 전체 모델 및 안정된 학습을 위한 모델의 설계가 복잡하다. 그래서 일반적인 모델과 다르게 좀더 세심한 모델링과 학습 전략을 필요로 한다.
기타 등.. 이 survey 논문에서는 SR 관련 방법을 소개한다. 끝.
'Research > Paper' 카테고리의 다른 글
| Deep Convolutional Neural Network for Image Deconvolution (0) | 2021.10.05 |
|---|---|
| YOLOv3: An Incremental Improvement (0) | 2021.10.05 |
